jueves
11 AbrApache Spark: Introducción, qué es y cómo funciona
Apache Spark es un framework de programación para procesamiento de datos distribuidos diseñado para ser rápido y de propósito general. Como su propio nombre indica, ha sido desarrollada en el marco del proyecto Apache, lo que garantiza su licencia Open Source.
En nuestro máster de Big Data e IA, tratamos a fondo esta herramienta en varios de nuestros módulos. Por eso, debido a su importancia, queremos dedicar este post a profundizar más en los entresijos de este framework de programación.
Además, podremos contar con que su mantenimiento y evolución se llevarán a cabo por grupos de trabajo de gran prestigio, y existirá una gran flexibilidad e interconexión con otros módulos de Apache como Hadoop, Hive o Kafka.
Parte de la esencia de Spark es su carácter generalista. Consta de diferentes APIs y módulos que permiten que sea utilizado por una gran variedad de profesionales en todas las etapas del ciclo de vida del dato.
Dichas etapas pueden incluir desde soporte para análisis interactivo de datos con SQL a la creación de complejos pipelines de machine learning y procesamiento en streaming, todo usando el mismo motor de procesamiento y las mismas APIs.
Apache Spark: Su relación con Hadoop
En el ámbito del análisis de grandes volúmenes de datos, una de las cuestiones que frecuentemente surge es la relación entre Spark y Hadoop. Muchos se preguntan si Spark es simplemente otra tecnología que compite con Hadoop, el conocido framework de procesamiento distribuido. Sin embargo, una visión más precisa sería considerar a Spark como la evolución natural de Hadoop. Aunque Hadoop ha sido una herramienta revolucionaria, sus capacidades se han visto algo limitadas debido a su rigidez estructural, particularmente en lo que respecta a la explotación de las capacidades del procesamiento distribuido.
Spark no solo aborda estas limitaciones, sino que las supera mediante varias innovaciones significativas. Una de las más destacadas es el procesamiento en memoria, una característica que permite a Spark realizar operaciones mucho más rápidas que Hadoop. Al mantener los datos en la RAM del cluster, Spark reduce drásticamente la necesidad de operaciones de lectura y escritura continuas a disco, lo cual es un requisito frecuente en los procesos de MapReduce de Hadoop.
Otra evolución importante de Spark respecto a Hadoop es su capacidad para realizar análisis interactivo utilizando SQL, de manera similar a cómo Hive opera sobre Hadoop. Esto es posible gracias a Spark SQL, un componente de Spark que permite que los usuarios ejecuten consultas SQL para analizar datos integrados con la facilidad de uso y la flexibilidad que ofrece Spark, haciendo posible un análisis más ágil y adaptativo.
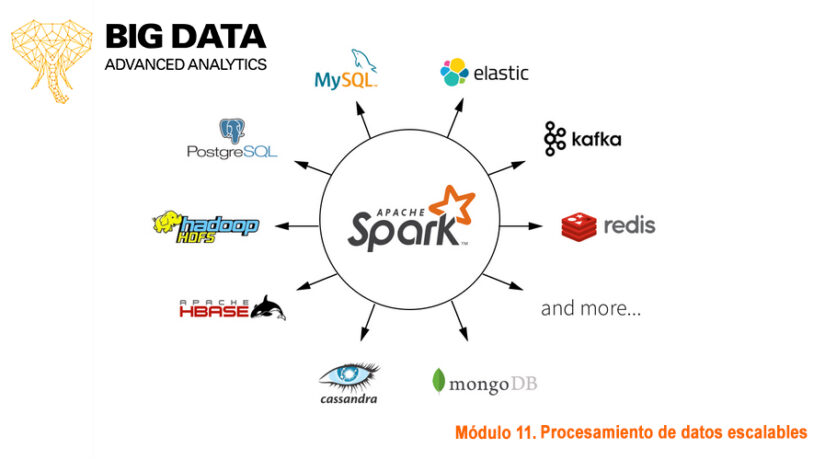
Además, Spark ofrece una mayor facilidad para interactuar con múltiples sistemas de almacenamiento persistente. Esto se traduce en una integración más fluida con una variedad de fuentes de datos, desde sistemas de archivos tradicionales como HDFS (Hadoop Distributed File System) hasta plataformas más modernas como Cassandra o HBase. Esta flexibilidad es vital para las organizaciones que buscan implementar soluciones de big data que se adapten a diferentes necesidades y escenarios de almacenamiento.
En resumen, Spark representa una mejora significativa sobre las capacidades de Hadoop, proporcionando una plataforma más flexible, rápida y eficiente para el procesamiento de grandes datasets. Con estas características, Spark no solo se posiciona como sucesor de Hadoop, sino como una herramienta esencial en el futuro del procesamiento de datos a gran escala.
Apache Spark: ¿Cómo funciona?
Apache Spark es un motor de procesamiento distribuido responsable de orquestar, distribuir y monitorizar aplicaciones que constan de múltiples tareas de procesamiento de datos sobre varias máquinas de trabajo, que forman un cluster.
Como ya hemos mencionado, es posible leer los datos desde diferentes soluciones de almacenamiento persistente como Amazon S3 o Google Storage, sistemas de almacenamiento distribuido como HDFS, sistemas key-value como Apache Cassandra, o buses de mensajes como Kafka.
A pesar de ello, Spark no almacena datos en sí mismo, sino que tiene el foco puesto en el procesamiento. Este es uno de los puntos que lo diferencian de Hadoop, que incluye tanto un almacenamiento persistente (HDFS) como un sistema de procesamiento (MapReduce) de un manera muy integrada.
Es importante hablar de la velocidad de procesamiento: la clave es la posibilidad que ofrece Spark para realizar el procesamiento en memoria. Esto, y la extensión del popular MapReduce para permitir de manera eficiente otros tipos de operaciones: Queries interactivas y Procesamiento en Streaming.
Apache Spark: ¿Cuáles son sus funciones?
Respecto a su propósito general, la virtud de Spark es estar diseñado para cubrir una amplia gama de cargas de trabajo que previamente requerían sistemas distribuidos diferentes.
Éstos sistemas incluyen procesamiento batch, algoritmos iterativos, queries interactivas, procesamiento streaming… a menudo empleados todos ellos en un pipeline típico de análisis de datos.
Por último, hemos dicho que Spark es flexible en su utilización, y es que ofrece una serie de APIs que permiten a usuarios con diferentes backgrounds poder utilizarlo. Incluye APIs de Python, Java, Scala, SQL y R, con funciones integradas y en general una performance razonablemente buena en todas ellas.
Permite trabajar con datos más o menos estructurados (RDDs, dataframes, datasets) dependiendo de las necesidades y preferencias del usuario.
Además, como hemos ido viendo a lo largo del post, se integra de manera muy cómoda con otras herramientas Big Data, en especial aquellas procedentes del proyecto Apache.
En particular, como era de esperar, cabe destacar la integración con Hadoop: Spark puede ejecutarse en clusters Hadoop y acceder a los datos almacenados en HDFS y otras fuentes de datos de Hadoop (Cassandra, Hbase, Kafka…).
En definitiva, Apache Spark se ha establecido como una solución de vanguardia en el mundo del big data, superando a Hadoop en velocidad, eficiencia y flexibilidad. Al proporcionar un marco más ágil para el procesamiento de datos masivos, Spark facilita a las empresas y a los investigadores la capacidad de obtener insights rápidos y efectivos, esenciales para tomar decisiones informadas en tiempo real. Su compatibilidad con múltiples lenguajes y plataformas de almacenamiento, junto con su capacidad para manejar diversas cargas de trabajo, desde procesamiento por lotes hasta análisis en tiempo real, lo convierten en una herramienta indispensable en el ecosistema de datos moderno.
Para quienes buscan aprovechar al máximo sus datos, la elección de Spark representa un paso adelante hacia sistemas más integrados y eficientes. Con un panorama tecnológico que evoluciona constantemente, la adopción de herramientas como Spark no solo mejora los procesos existentes sino que también abre nuevas posibilidades en la exploración de datos.
Así, Spark no solo sigue siendo relevante, sino que continúa siendo una pieza central en la estrategia de datos de muchas organizaciones. Con esto en mente, el futuro del procesamiento de datos promete ser tan dinámico como lo es el desarrollo de Spark.





Deja un comentario