Opiniones de nuestros alumnos…
Las opiniones de nuestros alumnos actuales nos motivas para seguir con nuestra IV Edición del Máster en Big Data de la UMA en modo no presencial, debido a la crisis provocada por el coronavirus.
Leer más
Las opiniones de nuestros alumnos actuales nos motivas para seguir con nuestra IV Edición del Máster en Big Data de la UMA en modo no presencial, debido a la crisis provocada por el coronavirus.
Leer más
¿Cuántas veces tenemos gráficos o informes de resultados que no entendemos correctamente? Esto pasa muy a menudo. La visualización de datos se ha convertido en un punto clave para comunicar, impactando en las decisiones de las empresas.
Leer más
Debido a la suspensión de la actividad docente presencial en la UMA como consecuencia de la pandemia de coronavirus CoVid-19, el máster se ha convertido (temporalmente) de semipresencial en “a distancia” en menos de 24 horas, estableciéndose los mecanismos necesarios para continuar con la docencia sin que hayamos perdido ni una sóla clase…
Leer más
Manuel Ujaldón, CUDA fellow desde 2012, Deep Learning Ambassador de NVIDIA y profesor de la Universidad de Málaga, ya es un habitual en Xataka. Tras entrevistarle en 2012, 2016 y 2018 para analizar el segmento de las tarjetas gráficas, vuelve con nosotros para tratar de descubrirnos cuál es el estado actual de un mercado en constante ebullición.
Leer más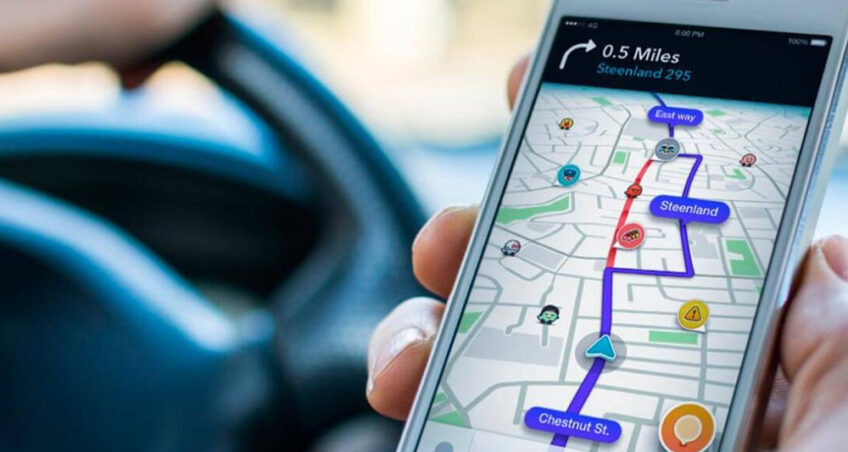
Esta es una típica alerta emitida por la herramienta israelí de navegación Waze, lanzada al mercado hace más de una década y comprada por Google en 2013. Waze recopila datos sobre el tráfico en tiempo real: vehículos, semáforos, accidentes de tráfico, obras actuales, etc. A través del crowdsourcing, o colaboración masiva de sus propios usuarios. De esta forma consigue que unos conductos ayuden a otros a llegar a su destino de una forma más rápida, evitando atascos y zonas de peligro.
Leer másExisten varios modos de instalar Apache Spark: Modo Standalone : Tenemos el HDFS (Hadoop Distributed File System), es decir, el sistema de archivos distribuido de Haddop, y por encima estaría Apache Spark. Hadoop V1 (SIMR) : Tenemos el HDFS y por encima Map Reduce, y por encima del mismo estaría Apache Spark. Hadoop V2 (YARN) : Tenemos nuestro HDFS
Leer más
Apache Spark nació en 2009 en la Universidad de Berkeley, y actualmente se encuentra en la versión 2.3.0.
Leer más
El análisis avanzado de datos masivos, ciencia del Big Data, se ha convertido en los últimos años en uno de los pilares fundamentales de la digitalización del siglo XXI.
Leer más
La intención del Big Data es simple, hacer la vida más fácil a todo el mundo basándonos en la información que tenemos pero que hasta el momento no teníamos capacidad de gestionar, así como ayudar a las empresas a vender más y mejor a ofrecerles esta información útil y necesaria.
Leer más
Estamos hablando de profesionales altamente cualificados, relacionados con matemáticas, informática, estadísticas, algoritmia, ingeniería del software, etc. Actualmente, este talento no abunda y, además, los profesionales de este ámbito son difíciles de retener en las empresas.
Leer más
